 @ GS칼텍스
@ GS칼텍스2024Full-Stack
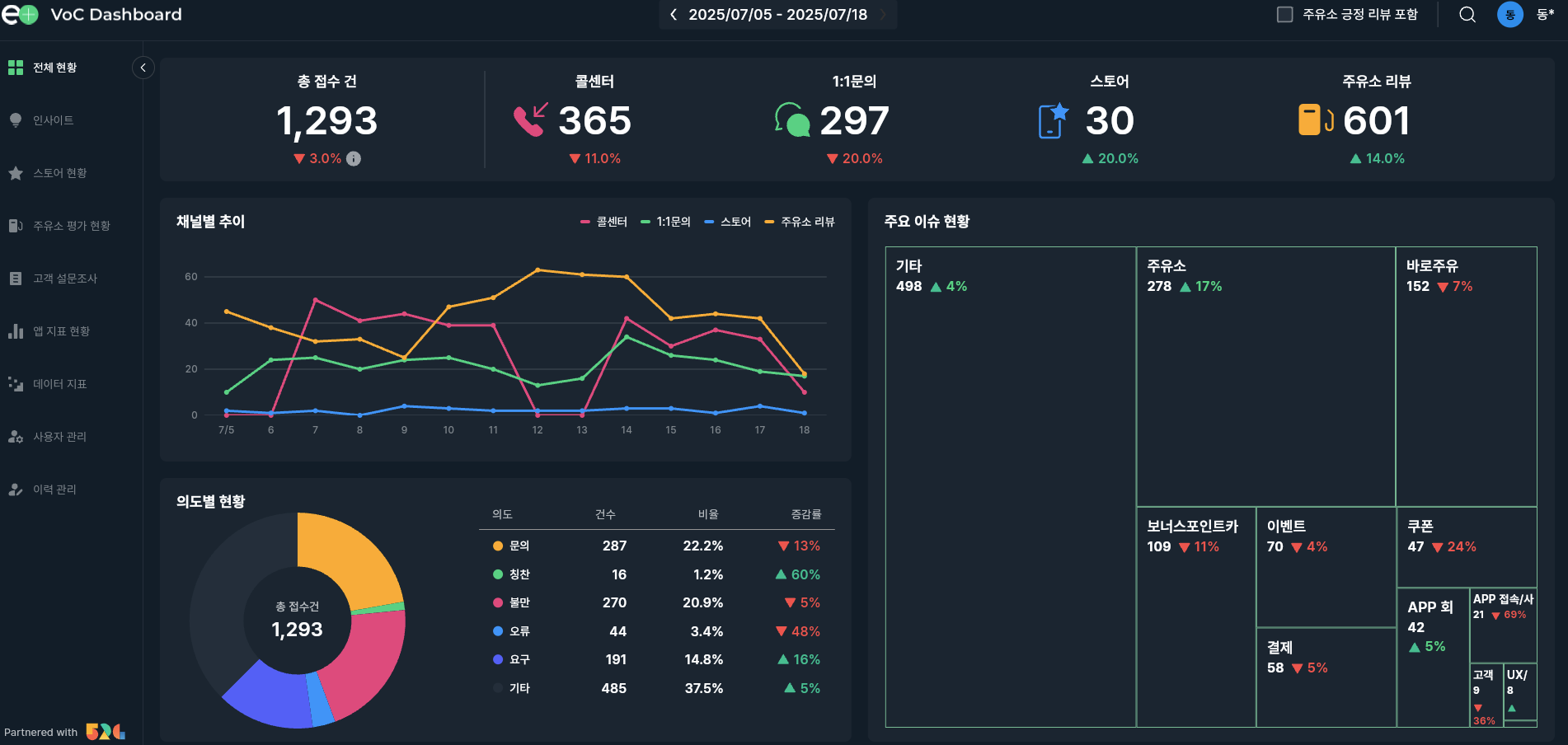
GS Caltex VOC AI Dashboard
Sole architect and engineer of the VOC AI Dashboard, manual review replaced by 1,000+/day auto-classification across 4 integrated channels.
View details
Narrowed scope from a product angle and pulled "what comes after retirement" into an MVP in 2 months with a single LLM call.
A senior who finished the test stayed stuck on the same line — 'so what should I actually do next?' The multiple-choice test ended at the score; the human coach was locked inside an expensive 1:1 room. From score to job — that last step had never been answered by a system.
That one step was the product. Build the full pipeline from test result to 8,000-job match and a result page, put it into a shape any user could hold in their hand without a coach — let the system answer with the insight of the coach most people could not reach.
Field notes
The test stopped at the score
A multiple-choice result alone never carried anyone into the 8,000-job pool.
The coach was stuck inside a room
Qualitative interpretation was expensive and out of reach for most people approaching retirement.
"What comes after retirement" always depended on a person
There was no system that connected one person's aptitude to a job.
There was no time to run a comparison ablation. The Gemini API gave stable Korean responses, the Flutter integration cost was low, and as a single-model call it was something I could validate inside two months. Comparison work belonged after PMF, so I let it go and moved on.
No resources to build complex RAG or an eval pipeline. Inside the schedule, raising single-call output stability was the most reasonable lever — bundled a persona system prompt (career-coach tone, polite Korean honorifics), output-format enforcement (section structure, paragraph length), and a hallucination guard (no invented jobs, no flat assertions) into one prompt, and let that single call carry the trustworthiness of the senior result page.
On a two-month solo schedule, building the greenfield backend in one service was less reasonable than putting each piece where it does its best work. Auth/push/analytics on Firebase, structured data, RLS, and the result-page archive on Supabase — the responsibility line was drawn from the first commit so I had the smallest possible surface to build by hand. Result pages that need to be stored and reread per user belong on the RLS side, which is Supabase.
No vector matching, no 8,000-attribute DB, no RAG. Every decision passed through the same two questions — does this finish in two months? does it raise the senior result page's trustworthiness enough? Only the items that answered yes to both went in. Picking the right places not to build was the real engine of a solo ship.
The client's one-liner — "an AI career-diagnosis app" — was not shippable on its own. In weekly sync, I pulled the vague mission into concrete spec. The single phrase "for seniors" produced the Korean polite tone, the simple flow, and the RLS-archived result page; "8,000-job matching" produced the single-Gemini-call-with-multi-guard decision. Translating the one-line mission into spec together was the starting line of a solo two-month ship.
Play Store rating
4.6 / 5.0
Stable post-launch ops
Downloads
1,000+
Per Google Play (April 2026)
MVP shipped
2 months
Core only, solo full-stack
“An engineer who only makes shippable decisions, ties the AI down to a single call, and lets the Play Store numbers do the answering.”
Spotted the gap: what a retiring senior actually wants is neither a raw test score nor a human coach.
Took a one-line vague mission and, in weekly sync with the client, pulled it into concrete spec — from "for seniors" into a polite tone, a simple flow, and RLS-protected result pages.
Bundled persona, format, and hallucination guards into a single Gemini call, split the greenfield backend between Firebase and Supabase by responsibility, shipped MVP in two months.
Google Play 4.6, 1,000+ downloads, MVP shipped in two months.
More work

