 @ GS칼텍스
@ GS칼텍스2024풀스택
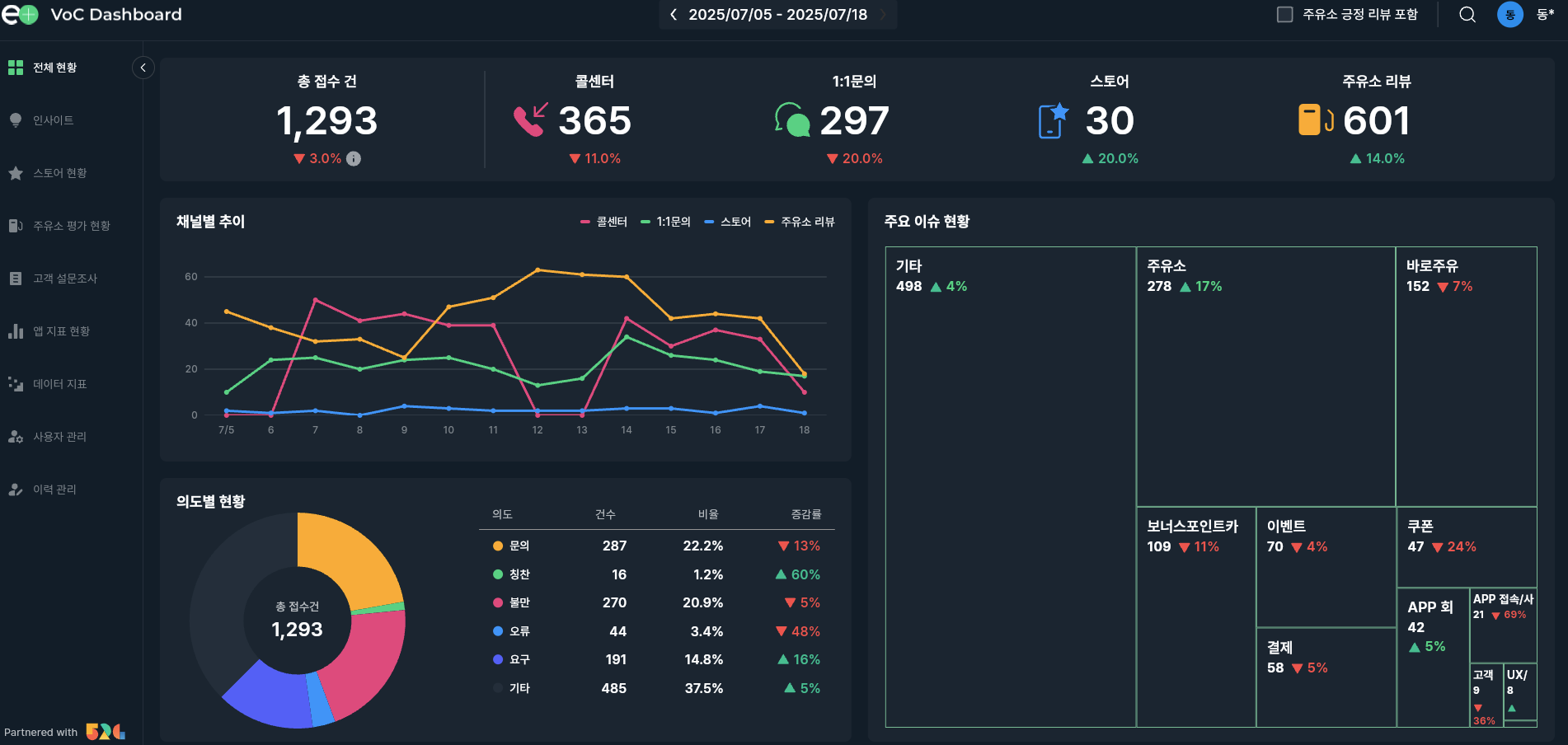
VOC AI 대시보드 - GS칼텍스
VOC AI 대시보드 단독 설계·구현 — 수작업 → 1000+/day 자동 분류, 4채널 통합
자세히 보기
프로덕트 관점으로 스코프를 좁혀, 퇴직 다음의 답을 한 호출 LLM 으로 2개월 만에 MVP 로 뽑은 사례.
검사지를 받은 시니어 한 명이 같은 자리에 멈췄다 — '그래서, 나는 다음에 뭘 해야 하지?' 객관식 검사지는 점수까지였고, 인간 코치는 1대1의 비싼 자리에 갇혀 있었다. 점수에서 직업까지 — 마지막 한 단계를 시스템이 답한 적이 없었다.
이 프로덕트가 풀어야 했던 건 그 한 단계였다. 검사 결과를 8천 직업 매칭과 결과지로 잇는 풀 파이프라인을, 코치 없이도 누구나 손에 쥘 수 있는 형태로 짓는 일 — 비싸고 닿지 못하던 코치 한 명의 통찰을 시스템이 대신 답하게 하는 일이었다.
관찰 노트
검사는 점수에서 멈췄다
객관식 결과만으로는 8천 직업 풀 어디로도 데려가지 못했다
코치는 자리 안에 갇혀 있었다
정성적 해석은 비싸고 접근성이 낮아 퇴직을 앞둔 대부분에게 닿지 못했다
퇴직 다음의 답은 늘 사람에 의존했다
한 사람의 적성을 직업과 맺어 줄 시스템이 없었다
비교 ablation 을 돌릴 시간 자체가 없었다. Gemini API 는 한국어 응답이 안정적이었고, Flutter 통합 비용이 낮았고, 2개월 안에 빠르게 검증 가능한 단일 모델 결정이었다. 비교 검증은 PMF 다음 단계의 일이라 판단하고 다음으로 넘어갔다.
복잡한 RAG 나 평가 파이프라인을 짤 자원이 없었다. 한 호출의 출력 안정성을 끌어올리는 게 일정 안에서 가장 합리적이었다 — 페르소나 시스템 프롬프트(경력 코치 톤·시니어 친화 존댓말), 출력 형식 강제(섹션 구조·문단 길이), hallucination 가드(없는 직업·없는 단정 금지) 를 한 프롬프트에 묶어, 한 호출이 시니어 결과지의 신뢰도를 책임지게 했다.
그린필드 백엔드를 한 서비스로 다 짓는 것보다, 각자 잘하는 자리에 두는 게 2개월 단독 일정 안에서 합리적이었다. Auth/Push/Analytics 는 Firebase, 정형 데이터·RLS·결과지 보관은 Supabase 로 첫 줄부터 책임 경계를 갈라, 직접 짤 자리를 최소로 줄였다. 시니어 결과지가 사용자별로 안전히 보관·재조회되는 자리는 RLS 가 있는 Supabase 쪽이 맞다고 봤다.
벡터 매칭도, 8천 attributes DB 도, RAG 도 짓지 않았다. 모든 결정이 같은 질문을 거쳤다 — 이게 2개월 안에 끝나는가? 시니어 결과지의 신뢰도를 충분히 높이는가? 답이 둘 다 yes 인 것만 들어갔다. 더 만들지 않을 자리를 정확히 고른 것이 단독 출시의 진짜 엔진이었다.
클라이언트가 준 한 줄 — "AI 경력진단 앱" — 으로는 출시할 수 없었다. 매주 호흡을 맞춰가며 모호한 미션을 구체 스펙으로 도출·정의했다. "시니어 대상"이라는 한 단어에서 한국어 존댓말 톤·단순 플로우·RLS 보관 결과지까지 끌어냈고, "8천 직업 매칭"에서 Gemini 한 호출 + 다중 가드라는 결정을 끌어냈다. 한 줄 미션을 함께 스펙으로 옮긴 일이, 2개월 단독 출시의 출발선이었다.
Play Store 평점
4.6 / 5.0
출시 후 안정 운영
다운로드
1,000+
Google Play 표기 (2026-04 기준)
MVP 출시
2개월
핵심만 짜고 1인 풀스택
“출시할 수 있는 결정만 들이고, AI 를 한 호출에 단단히 묶으며, Play 위 숫자로 답하는 엔지니어.”
퇴직 시점 시니어가 받을 답이 검사 점수도 인간 코치도 아니라는, 시장 빈 자리를 짚어냄
한 줄로 받은 모호한 미션을, 매주 클라이언트와 호흡 맞춰 구체 스펙으로 도출·정의 — "시니어 대상"에서 존댓말 톤·단순 플로우·RLS 보관 결과지까지
Gemini 한 호출에 다중 가드(페르소나·형식·hallucination)를 묶고, 그린필드 백엔드를 Firebase × Supabase 책임으로 갈라 2개월 만에 MVP 출시
Google Play 4.6 / 1,000+ DL / 2개월 MVP 출시
More work

